PinnedDavid ChongMy Medium Stories (Updated Weekly)Reading lists included (Last updated 10 Jan 2024)Jul 27, 2022Jul 27, 2022
PinnedDavid ChonginTowards Data ScienceI had no idea how to write code two years ago. Now I’m an AI engineer.My journey in its rawest formDec 26, 201960Dec 26, 201960
David ChongI left AI to do software. Here’s why.If AI is a superpower, software is the vessel.Apr 292Apr 292
David ChonginLevel Up CodingTechnical (Leetcode-style) Interview Cheat Sheet (Python)Beyond the basics — Tips & tricks to ace your next technical interviewJan 151Jan 151
David ChongVan Gogh, Picasso and Da Vinci reimagines Hello Kitty using DALL·E 2How good is DALL·E at style transfer? An evaluation by a Machine Learning engineerJan 10Jan 10
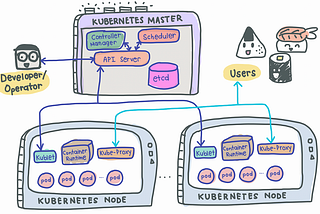
David ChonginLevel Up CodingKubernetes: What actually happens when we perform kubectl apply?A deep dive under the hoodDec 11, 20231Dec 11, 20231
David ChonginLevel Up CodingBeware Of These Common Misconceptions In Software Design And EngineeringDon’t take advice too literallyAug 11, 20221Aug 11, 20221
David ChonginThe StartupWhy I’m Not Quitting My Day Job As A ML Engineer To Write Full-TimeAnd maybe why you shouldn’t tooAug 7, 20221Aug 7, 20221